Research Gap
- ML security: Most work focuses on attacks via model inputs/outputs, ignoring the broader data flow.
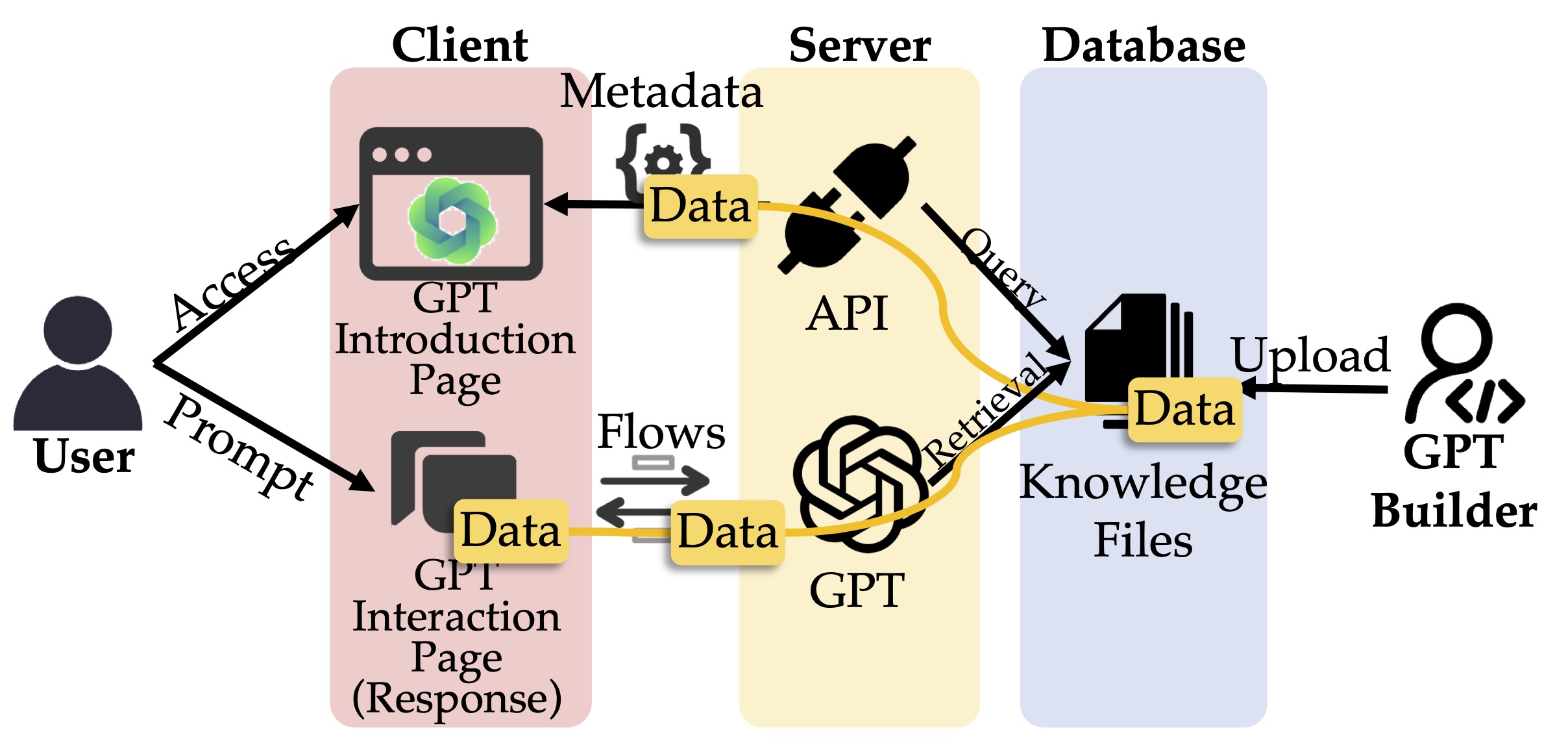
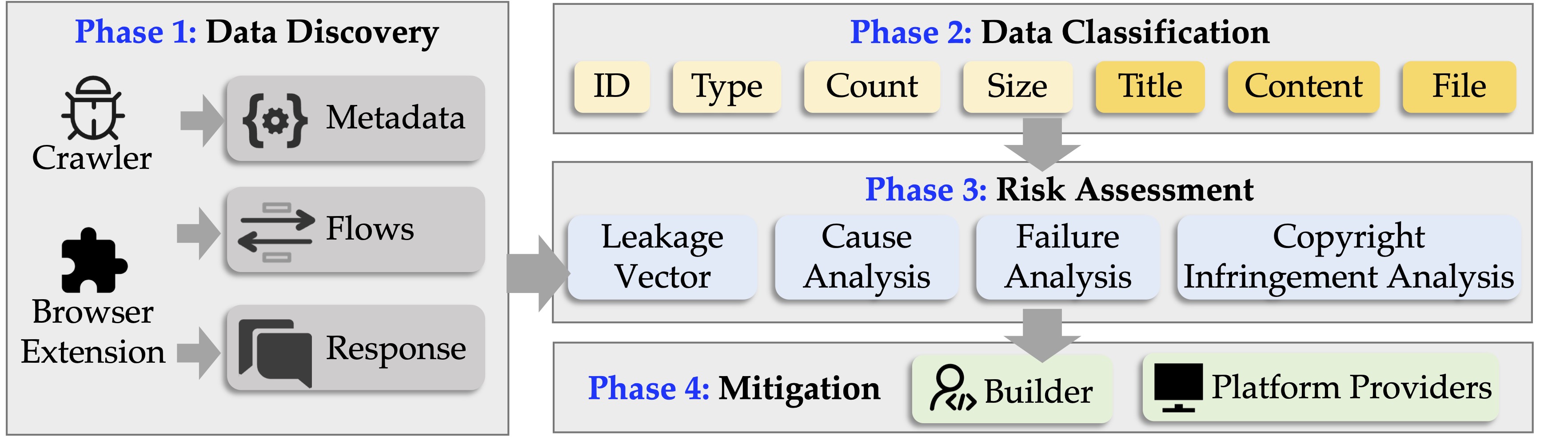
- Web security: GPTs handle files across clients, servers, and databases, but leakage risks in the full data supply chain are underexplored.